Retours sur la mise en ligne de wallabag.it
Bon, on peut souffler un peu. La mise en ligne de wallabag.it s'est plutôt bien passé : beaucoup de retours, quasiment que des retours positifs. Un article sur NextInpact (un peu critique, mais ces critiques sont justifiées donc bon).
Il a fallu surtout supporter l'effet Capital (à une moindre échelle, je le reconnais).
Rapidement, des utilisateurs sont arrivés, se sont créés un compte et ont décidé de récupérer leurs milliers d'articles de Pocket ou Instapaper : des gens ont plus de 15.000 articles chez Pocket. Mais vous êtes fous ? Passons.
Ça a surtout permis de tester à grande échelle l'import asynchrone de wallabag. Pour tester, on a testé.
Dans un premier temps, j'avais mis en place Redis pour stocker les articles et les traiter de manière asynchrone. wallabag supporte aussi RabbitMQ, mais Redis étant plus léger, plus simple à installer, ça me paraissait un bon compromis.
J'avais lancé les workers (script qui consomme les articles stockés dans Redis pour les récupérer en ligne et les stocker dans la base de wallabag) en ligne de commande, classiquement. Quasiment une dizaine de workers pour Pocket, pareil pour Instapaper et tous les autres (environ 70 workers).
Ça marchait. Presque.
Il ne fallait pas trop charger la mule, sinon le CPU était vite sous l'eau. Problème constaté : certains workers mourraient, il fallait donc les relancer. Hop, un cron qui vérifie régulièrement le nombre de workers qui tournent et relance ce qu'il faut pour qu'on ait toujours nos 70 workers. Une ébauche de ce cron se trouve ici.
Pendant que les workers tentaient despérément de consommer les articles, les utilisateurs, eux, continuaient d'envoyer des articles. On est très rapidement arrivé à 100.000 articles à importer. CENT. MILLE. En moins de 24h.
@bourvill, qui développe l'appli wallabag pour iOS, me conseille de ne pas laisser tourner mes worker indéfininement, mais de les faire consommer quelques messages, puis de les tuer pour les relancer. Y'a eu un peu de mieux. Mais c'était pas la forme non plus.
Il me parle ensuite de supervisor. Hop, à la poubelle mon cron, supervisor c'est génial. On lui dit : "voici une commande à surveille : si elle meurt, tu la relances."
Extrait de configuration pour mes workers Pocket par exemple :
[group:pocket-workers]
[program:pocket-01]
command=php bin/console rabbitmq:consumer -e=prod import_pocket -w -vvv
directory=/var/www/app.wallabag.it/current/
autostart=true
autorestart=true
startretries=3
stderr_logfile=/var/log/import-workers/pocket.err.log
stdout_logfile=/var/log/import-workers/pocket.out.log
user=www-data
[program:pocket-02]
command=php bin/console rabbitmq:consumer -e=prod import_pocket -w -vvv
directory=/var/www/app.wallabag.it/current/
autostart=true
autorestart=true
startretries=3
stderr_logfile=/var/log/import-workers/pocket.err.log
stdout_logfile=/var/log/import-workers/pocket.out.log
user=www-data
supervisor est aussi plus pratique pour arrêter / démarrer / ajouter de nouveaux workers.
Bon, c'était mieux pour gérer les workers, mais les problèmes de performance étaient toujours là.
Au bout de 48h, je décide de couper les imports. Le temps de laisser Redis digérer les 50.000 articles avec seulement quelques workers : le fait d'en faire tourner trop faisait ramer l'appli en elle-même, certains utilisateurs avaient des timeout.
Après avoir discuté avec @j0k3r et @bourvill des optimisations possibles, je décide d'abandonner Redis pour installer RabbitMQ.
Et là, surprise : ça trace. Alors que RabbitMQ est plus lourd, il s'en sort mieux. Logique, il est fait pour ça (Redis n'étant à la base pas fait pour ça), si jamais un worker plante, on ne risque pas de perdre de messages. Et le bundle utilisé pour communiquer avec RabbitMQ est surement plus performant que la librairie PHP utilisée pour Redis.
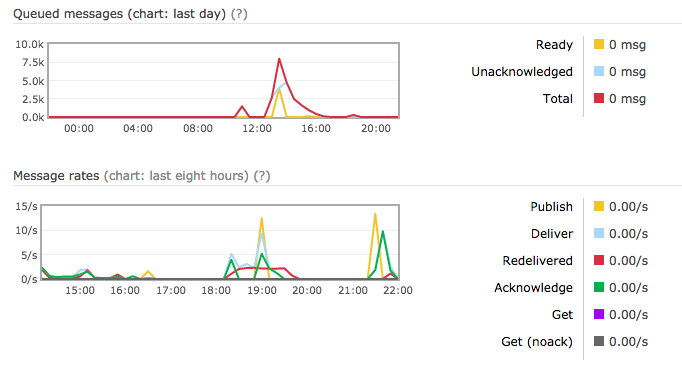
Joie donc. Je décide de faire un test grandeur nature : import de 8.000 articles depuis Pocket avec 15 workers. Pour les 4.000 premiers articles, ça a plutôt bien tourné. Et puis après, c'est devenu plus compliqué, les CPU ont commencé à chauffer.
Grrr.
De la RAM ajoutée et c'était mieux : je décide donc de réouvrir les imports à tout le monde après des tests de plusieurs milliers d'articles (Merci elpep, gnppn et lpenou).
@bourvill, toujours lui, me dit d'activer aussi la quality of service dans RabbitMQ : en gros ça permet de n'affecter que quelques messages à un worker, pour éviter qu'il les prenne tous (le gourmand) et il en laisse ainsi aux autres et le parallélisme peut ainsi fonctionner. J'ai donc appris que sans ça, j'avais beau lancer 42 workers pour une même queue, ça n'aurait rien changé.
Pendant ce temps, et comme depuis le début de l'aventure de toute façon, Benoit, de web4all (mon hébergeur), a toujours été là pour me soutenir, pour changer les perfs des serveurs (ajouter de la RAM, ajouter des CPU, surveiller les serveurs), tester plein de trucs. Un grand merci à lui !
Résultat : ce soir, ça semble se stabiliser, y'a des moments où les CPU chauffent encore, je tue les workers si vraiment les 4 CPU sont à plus de 80% chacun et ça repart. Donc encore un peu de boulot à faire niveau performance, mais c'est beaucoup plus supportable : ça importe et le site est utilisable.
Depuis 3 jours, mon ordi, c'est ça quasi en permanence : surveiller les CPU, voir le nombre d'articles en base, regarder ce qu'il reste à importer.
Aujourd'hui, tout s'est un peu calmé (et c'est pas plus mal), mais ça m'a permis de corriger des bugs dans wallabag (découverts via les imports), d'apprendre plein de choses et de voir que finalement, le service tournait pas trop mal :)
Quelques chiffres :
- 2500 visiteurs uniques en moins de 48h
- 160.000 articles importés en moins de 72h
- une base de données de 2,5 Go
- beaucoup de retours extrêmement positifs : merci !
C'était éprouvant, mais intéressant ! On continue !